Driven by artificial intelligence technology, text-to-speech (TTS) technology has evolved beyond mechanical and stiff tones into realistic, natural, and expressive speech forms.
From deep customization capabilities and emotion regulation to regional accent simulation and seamless cross-platform integration, the market demand for high-performance AI speech technology continues to rise.
Although Cartesia has carved out a position in the speech technology field, many users are still searching for more suitable alternative tools—tools that need to offer exceptional speech quality, user-friendly interfaces, and innovative AI platforms with flexible pricing. These tools can streamline content production workflows, accommodate video editing needs, and help global users apply AI-generated speech to online education, video creation, and various creative projects.
This article presents the top ten Cartesia alternatives, with ViiTor AI as a premium text-to-speech tool featured first.
Why Consider AI Alternatives to Cartesia?
Cartesia has gained attention in the AI speech technology field, but as a product launched in 2023, it has numerous limitations that make it difficult to meet all user scenarios. For example, compared to mature text-to-speech tools with vast natural speech and regional accent libraries, Cartesia's speech library still has a significant gap.
For enterprises that need to maintain a unified brand voice image across different markets, Cartesia's AI speech offers relatively limited options in terms of deep customization, emotion regulation, seamless integration with existing workflows, and other advanced AI features.
Scalability is also a crucial consideration. While Cartesia shows potential, large enterprises or small institutions planning large-scale deployments of related technologies often require professional technical support, detailed documentation, and flexible pricing schemes. Mature platforms that can provide customized solutions have significant advantages in these areas.
Choosing alternatives to Cartesia enables enterprises to gain market-proven quality assurance, more comprehensive speech customization capabilities, and user-friendly tools, thereby simplifying content creation and video editing workflows and delivering professional-quality video content to global audiences.
Top Ten Cartesia Alternatives
1. ViiTor AI
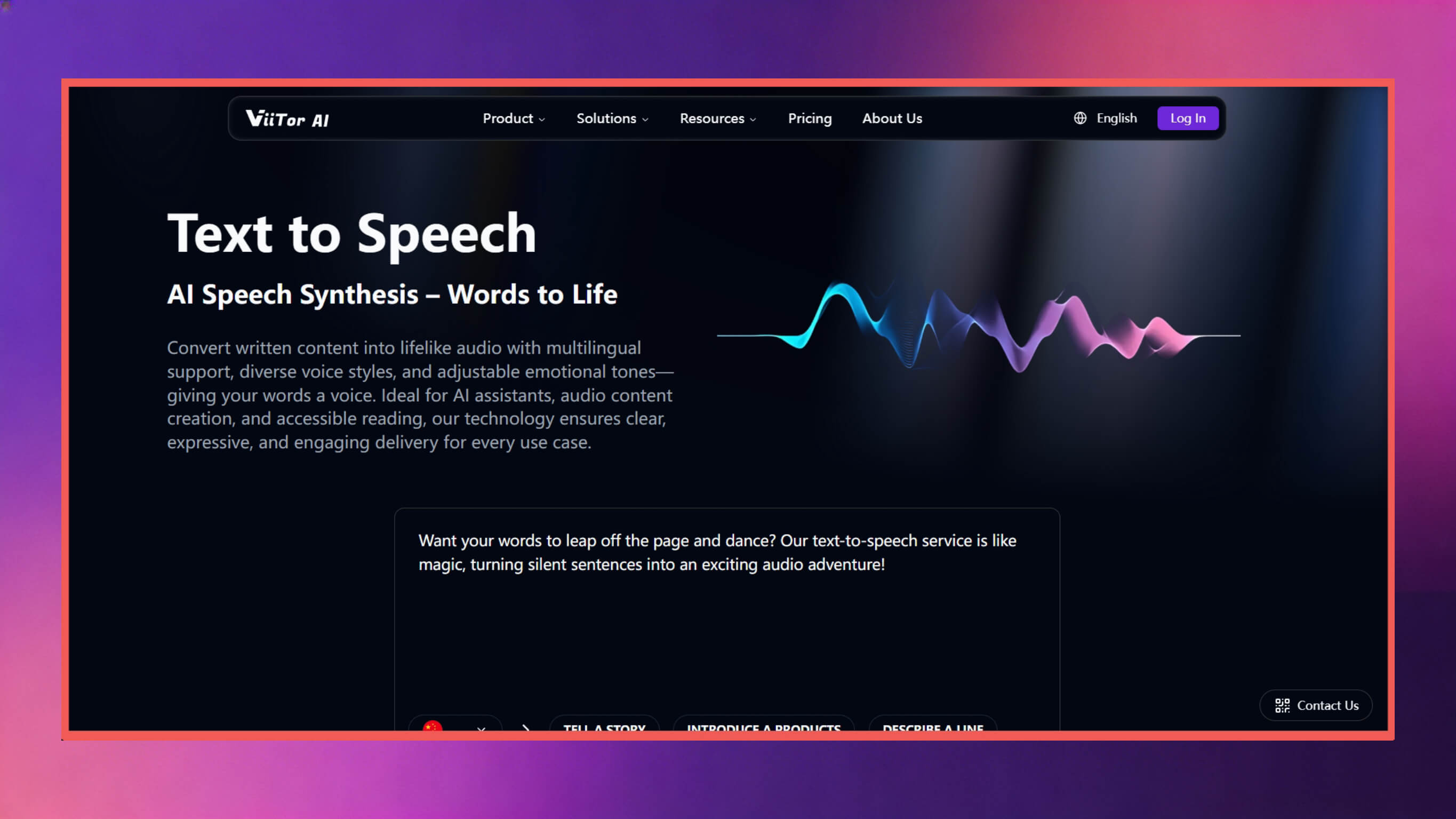
ViiTor AI is the most worthwhile first-choice alternative for Cartesia users, with its key features including:
Speech Quality and Naturalness: ViiTor AI supports 19 languages and over 1,000 voices, allowing flexible adjustment of speech rate and volume, fine-tuning of emotional details, and achieving a speech pronunciation accuracy rate of 99.38%, combining both fidelity and naturalness.
Customization and Voice Cloning: Users can record their personal voice and complete cloning to meet personalized voice usage needs.
Pricing and Scalability: Offers free plans and multiple paid plans, with paid plans starting at $9.9 per month, while providing customized plan services according to user needs.
Differences from Cartesia:
- ViiTor AI offers 19 languages and over 1,000 ultra-realistic voices, while Cartesia currently supports only 15 languages, with speech coverage not matching ViiTor AI.
- ViiTor AI includes multiple voice styles and tone templates suitable for commercial scenarios, while Cartesia's core focus is real-time speech services for developers.
- ViiTor AI is equipped with an intuitive no-code voiceover and video narration creation studio that can be operated without professional technical skills; Cartesia requires more technical integration work through APIs.
2. ElevenLabs
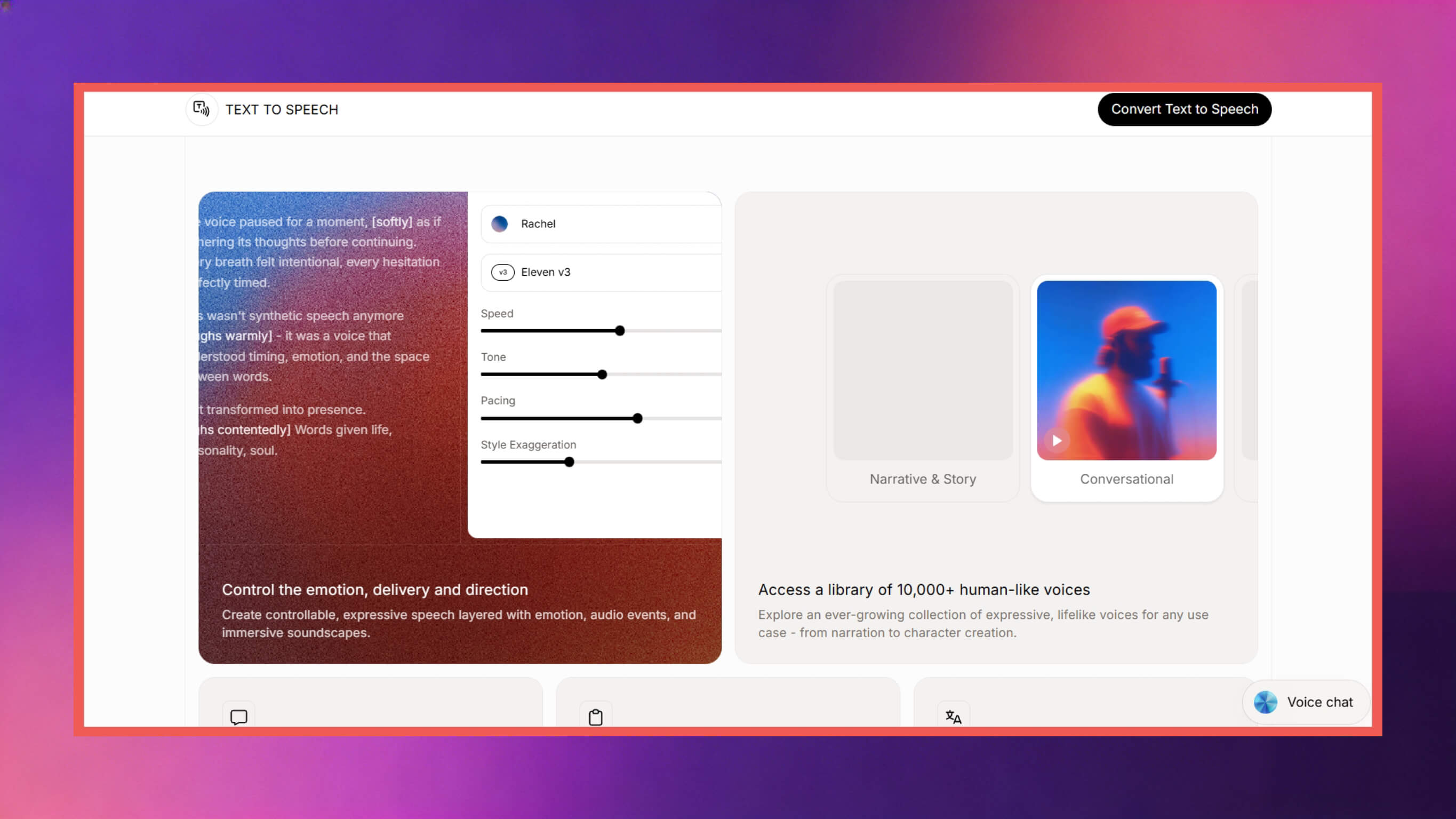
ElevenLabs is a strong competitor in the AI speech tool field, especially suitable for user groups with high requirements for voice cloning capabilities and emotional tone regulation.
Speech Quality and Natural Output: The tool's core advantages include rich emotional layers and natural tone transitions. During long text processing, it can achieve context-appropriate tone adjustments, enhancing the auditory experience.
Voice Cloning and Customization: Supports users uploading audio samples and cloning voice profiles, with fine-tuning of tone and style. Newer versions also include emotion tag selection features (such as [excited], [whisper], etc.).
Integration and Features: Provides powerful API and SDK tools, supporting voiceover production, multi-speaker content creation, and includes dedicated tools for voice agent deployment, adapting to diverse application scenarios.
Differences from Cartesia:
- In blind test evaluations, Cartesia claims superior speech naturalness and better latency performance than ElevenLabs.
- Cartesia adopts a state space model architecture optimized for streaming transmission, while ElevenLabs primarily uses a Transformer architecture, which has relatively higher latency.
- Cartesia requires only a small number of audio samples to complete instant voice cloning, while ElevenLabs typically needs more audio material to achieve the same effect.
- Cartesia supports device-side and local deployment, while ElevenLabs primarily operates in cloud deployment mode.
3. Play.ht
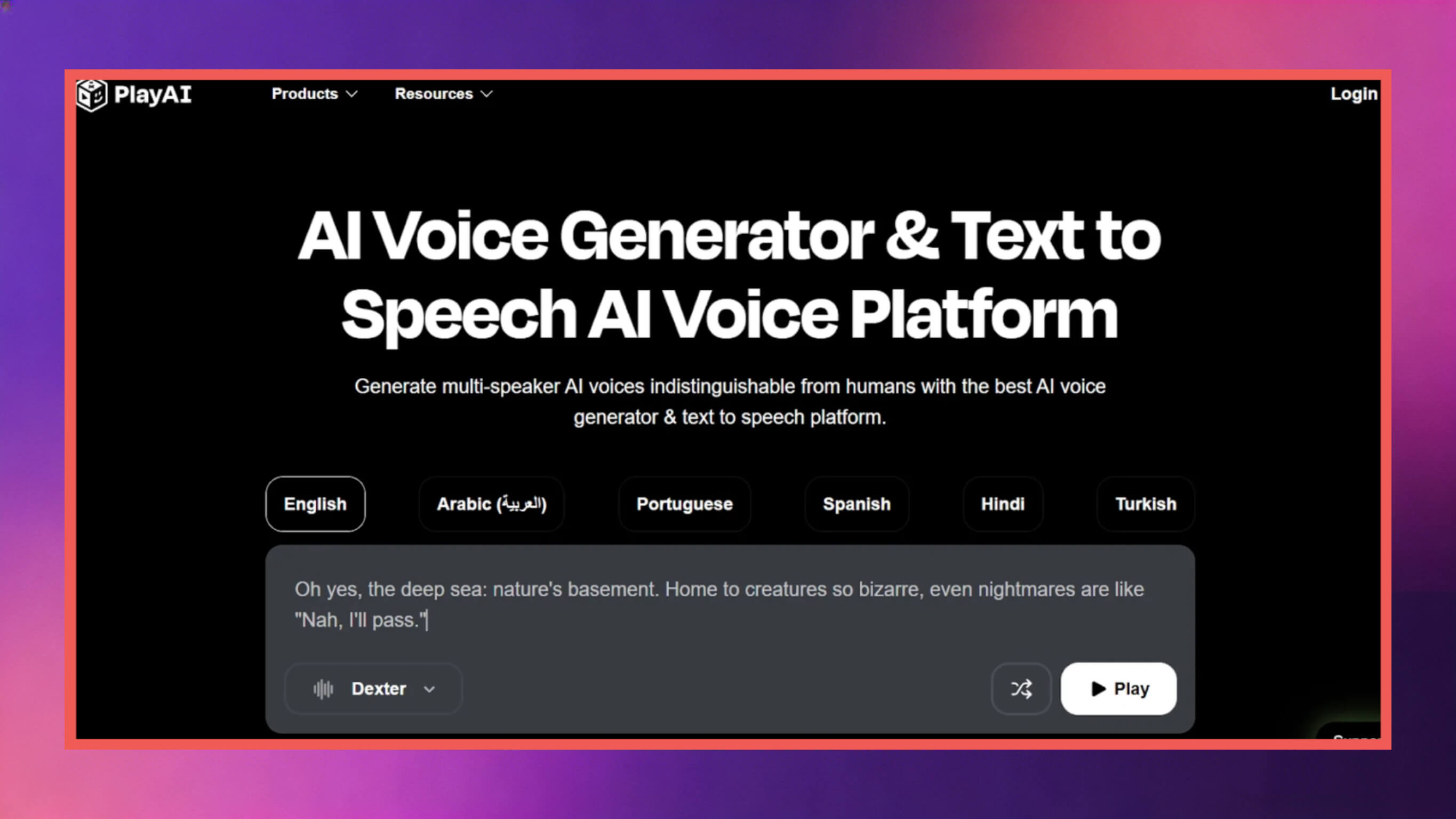
Play.ht is a highly versatile text-to-speech tool with core advantages in scalable services, voice diversity, and extensive language coverage capabilities.
Voice Library and Language Support: Provides over 206 text-to-speech voices across more than 30 languages and accents, meeting the usage needs of users in different regions.
Customization and Emotional Expression: Supports SSML control, custom pronunciation settings, voice tone adjustment, emotional style switching, and precise pause control, adapting to diverse creative needs.
Multi-speaker/Dialogue Features: Enables dialogue content creation and multiple voice switching within a single project, suitable for podcast production, storytelling, interactive script creation, and other scenarios.
API and Integration Capabilities: Provides low-latency text-to-speech API, supporting multiple format exports including MP3 and WAV, adapting to different application scenarios.
Differences from Cartesia:
- Cartesia's latency is only 40 milliseconds, significantly lower than Play.ht's typical 300 millisecond streaming transmission latency.
- Play.ht possesses voice resources of over 800 voices across more than 30 languages, with a massive voice library scale; Cartesia currently supports only 15 languages, with limited coverage.
- Play.ht focuses on optimizing low-latency API streaming transmission performance through its Play3.0-mini model, while Cartesia places greater emphasis on real-time transmission performance and device-side deployment adaptation capabilities.
- Play.ht's product positioning leans more toward content creators, while Cartesia focuses more on the needs of developers, voice agents, and real-time application scenarios.
4. Speechify
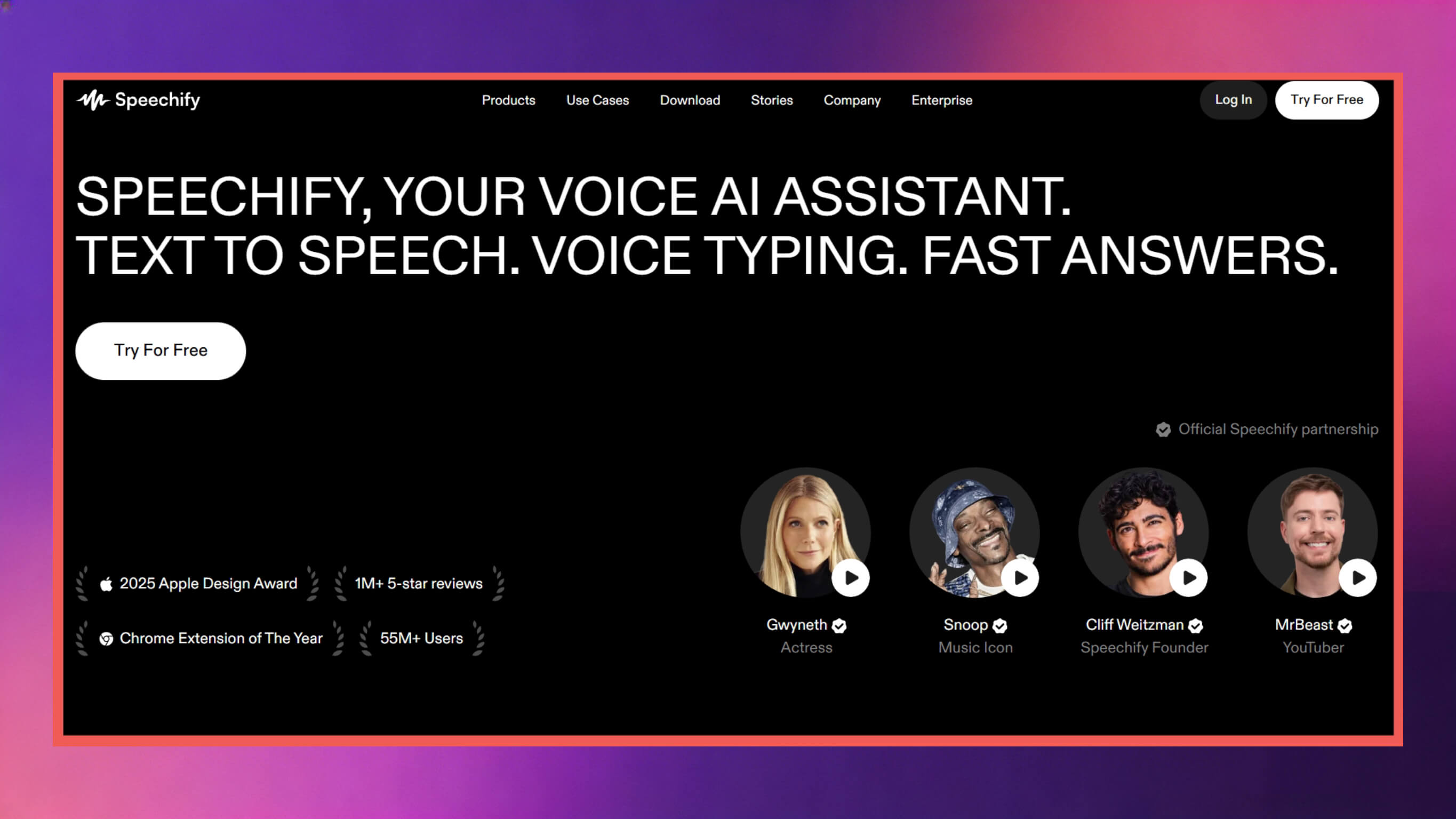
Speechify is positioned around text-to-speech convenience, usability, and efficiency, especially suitable for reading, learning, and content repurposing scenarios.
Speech Quality and Usability: Although slightly inferior to ViiTor AI and ElevenLabs in speech refinement, Speechify's speech performance is stable and practical, with naturalness that meets the needs of various daily usage scenarios.
Unique Features (Speech Rate Control, Reading): The core highlight is the speech rate adjustment feature, allowing users to increase listening speed up to 5 times, quickly converting long text into efficiently listenable audio content and improving information acquisition efficiency.
Integration and Transcription Features: Supports multi-language audio/video file-to-text conversion (transcription), which can be used for subtitle production, content repurposing, and other scenarios, adapting to diverse needs.
Differences from Cartesia:
- Speechify's product positioning is more oriented toward general consumers and reading applications, while Cartesia is specifically designed for developer APIs and real-time voice agent scenarios.
- Speechify does not promote low-latency real-time streaming capabilities, while Cartesia emphasizes initial audio output time of only 40 milliseconds, with superior real-time performance.
- Cartesia supports instant voice cloning and voice mixing features, which Speechify lacks.
- Cartesia supports device-side and local deployment, while Speechify relies entirely on cloud services.
5. WellSaid Labs
WellSaid Labs specializes in premium, sophisticated voiceover services, adapting to professional scenarios such as enterprises, studios, training course production, and brand promotion.
Speech Quality/Studio-Level Fidelity: WellSaid Labs focuses on creating natural and realistic speech effects with stable and coherent tones and pitches that meet professional scenario requirements, offering studio-level audio fidelity.
Customization and Brand Voice: Supports exclusive brand voice customization, ensuring cross-project voice consistency. High-tier paid plans also provide exclusive voice creation services.
Collaboration and Team Workflows: Equipped with team collaboration, version control, and project sharing functions, while providing enterprise-level security protection, adapting to team collaborative creation scenarios.
Integration and Usability: Provides API interfaces that can be smoothly integrated into various media processing workflows, adapting to professional creation needs.
Differences from Cartesia:
- Cartesia's latency is only 40 milliseconds, while WellSaid Labs' relatively higher latency affects response speed during use.
- Cartesia supports device-side and local deployment, while WellSaid Labs only provides cloud services.
- Cartesia supports unlimited-length speech requests, while WellSaid Labs may limit character counts or request lengths.
- Cartesia supports context accuracy adjustment, emotion and speech rate slider controls, synthetic voice mixing, and other features, while WellSaid Labs has relatively fewer voice design control options.
6. Lovo.ai
Lovo.ai targets creators who need high-quality speech, emotion control, and extensive language support, and who want to get started quickly without investing significant time in learning operational skills.
Speech Quality and Natural Output: Provides over 500 voices across more than 100 languages and accents, dedicated to creating human-like speech effects with rich emotional expressions that suit various creative scenarios.
Customization and Voice Cloning: Supports users uploading audio samples to complete voice cloning, while allowing flexible adjustment of tone, speech rate, pauses, and pitch to achieve personalization.
Integration and Workflows: Features a built-in browser editor (named Genny) that can quickly generate audio, synchronize video content, and support exports in WAV, MP3, and other formats, improving creation efficiency.
Pricing and Flexibility: Offers free plans and trial services, while introducing multiple paid plans. Upgrading unlocks more voice duration and advanced features, adapting to different budget needs.
Differences from Cartesia:
- Cartesia requires fewer audio samples to complete voice cloning, while Lovo.ai typically requires longer audio material to achieve stable voice cloning effects.
- Cartesia focuses on ultra-low-latency real-time application scenarios, while Lovo.ai is more suitable for voiceover production and batch audio generation needs.
- Cartesia supports device-side and local deployment, while Lovo.ai only provides cloud services.
- Cartesia's core competitiveness lies in developer APIs, while Lovo.ai places greater emphasis on user interface usability and the core needs of content creators.
7. Microsoft Azure Text-to-Speech
Microsoft Azure Text-to-Speech (part of Azure Speech Services) is a mainstream tool in the enterprise-level market, with core advantages in scalable deployment capabilities, compliance, and powerful integration adaptability.
Speech Quality and Natural Output: Employs advanced prosody modeling technology to provide high-quality neural speech with natural and smooth tones and refined emotional expressions, adapting to enterprise professional scenario requirements.
Customization and Custom Voice Creation: Supports enterprises in creating exclusive brand neural speech, achieving standardization and personalized unification of brand voice.
Integration/Deployment and Scalability: As an important component of the Microsoft ecosystem, it can seamlessly integrate into the larger Azure ecosystem, supporting containerization and edge deployment, while providing enterprise-level Service Level Agreements (SLAs) and compliance guarantees, adapting to enterprise-scale usage needs.
Pricing and Usage Model: Adopts a pay-as-you-go model, charging based on character count or audio duration, balancing flexibility and cost control.
Differences from Cartesia:
- Cartesia claims a latency range of 40-90 milliseconds, while Azure Text-to-Speech's typical latency is 300-800 milliseconds, with a significant gap in real-time performance.
- Cartesia supports device-side and local deployment, while Azure Text-to-Speech only provides cloud and server-side deployment options.
- Cartesia requires only a small number of audio samples to complete instant voice cloning, while Azure's custom voice functionality requires more data support and complex processing workflows.
- Cartesia performs better in industry evaluations and offers richer voice emotion control, while Azure Text-to-Speech focuses more on stability and adaptation to enterprise-level scenarios.
8. Descript
Descript integrates audio/video editing, voice cloning, and text-based editing functions, serving not just as a text-to-speech engine but as a comprehensive creative multimedia editing tool.
Speech Quality and Natural Output: Its Overdub feature can generate high-quality speech. Users need only input text to generate corresponding speech content with good fidelity, and supports quick audio modification through text editing.
Voice Cloning and Editing Workflow: Supports users cloning personal voice, after which audio content can be modified by editing text, with operations similar to document editing—convenient and efficient.
Audio/Video Tool Integration: As a professional multimedia editor, it integrates text-to-speech, audio editing, transcription, video alignment, content repurposing, and multiple other functions, enabling one-stop creation without switching between multiple tools.
Differences from Cartesia:
- Descript's core positioning is as an audio/video editing and transcription tool, with text-to-speech as an additional feature; Cartesia is a dedicated speech AI core engine with more targeted performance.
- Descript's text-to-speech functionality is not optimized for ultra-low-latency streaming, while Cartesia is specifically designed for real-time speech application scenarios with superior real-time performance.
- Cartesia provides developer API and device-side deployment options, adapting to development needs; Descript focuses on Graphical User Interface (GUI) operations, better suited to content creators' usage habits.
- Descript encompasses comprehensive multimedia functions including transcription, editing, voiceover, and video synchronization, while Cartesia focuses on high-performance speech synthesis and cloning core capabilities.
9. Synthesia
Synthesia specializes in AI video and voiceover integrated services—a comprehensive tool fusing visual and audio content, especially suitable for creative scenarios requiring synchronized video and speech generation.
Speech Quality and Speech Generation: Speech effects are stable, with naturalness meeting basic video narration needs, though still lagging behind premium pure text-to-speech platforms in refinement.
Video and Speech Creation: The core advantage lies in quickly generating videos through scripts, using AI avatars to achieve precise synchronization between lip movements and speech, supporting multi-language adaptation, and significantly lowering the barrier to video creation.
Usability: Designed specifically for non-technical users with streamlined operational workflows, allowing quick generation of explanatory videos, corporate training videos, and other content without professional video production skills.
Differences from Cartesia:
- Synthesia's core advantage lies in integrated video and avatar creation (lip sync + video generation), transcending pure speech service boundaries; Cartesia focuses on the speech AI field, offering superior speech performance.
- Cartesia emphasizes real-time low-latency text-to-speech capabilities, while Synthesia is optimized for pre-rendered video generation and is unsuitable for real-time streaming scenarios.
- Synthesia supports over 140 languages and avatar lip synchronization with extensive coverage; Cartesia supports only 15 languages and provides only speech services without video-related features.
- Cartesia supports device-side and local deployment, while Synthesia is a pure cloud-based video rendering platform dependent on network environment.
10. Amazon Polly
Amazon Polly is a legacy text-to-speech engine launched by Amazon, having undergone long-term market validation with the advantages of stable performance and developer-friendly accessibility, adapting to various enterprise and development scenarios.
Speech Quality and Voice Library: Built on advanced deep learning technology, it provides dozens of neural voices across multiple languages with good speech naturalness, adapting to diverse usage needs.
Customization and SSML/Dictionary Control: Supports SSML markup language control, custom dictionary settings, and refined prosody adjustment to achieve personalized speech customization.
Scalability and Integration: As an important component of the AWS ecosystem, it's suitable for users already using the AWS ecosystem. The Polly API can be flexibly embedded into various applications to implement speech streaming and other functions.
Cost and Flexibility: Adopts a flexible per-character pricing model with initial free tier availability for user experience and small-scale usage, with upgrade options based on later needs.
Differences from Cartesia:
- Cartesia's latency performance far exceeds Polly's typical network latency, offering superior real-time capabilities.
- Cartesia requires only a small number of audio samples to complete voice cloning, while Polly's custom voice creation functionality is relatively limited, making efficient personalized speech generation difficult.
- Cartesia supports device-side and local deployment, adapting to different environmental needs; Polly relies entirely on cloud services with insufficient flexibility.
- Cartesia claims to offer richer voice emotion control capabilities (supporting emotion adjustment, voice mixing, etc.), while Polly's neural voices tend toward static expression with relatively singular emotion conveyance.
Why Is ViiTor AI the Best Alternative to Cartesia?
Undeniably, Cartesia, as an emerging product, possesses strong innovation, and its technological breakthroughs demonstrate development trends in the text-to-speech field. However, for marketers, educators, podcast creators, and enterprises undertaking large-scale projects, a reliable, convenient, and efficient tool is more important than technological innovation buzzwords—ViiTor AI is exactly a safer and more cost-effective choice.
ViiTor AI is equipped with professional neural text-to-speech models, generating AI speech that closely matches human speech with almost imperceptible differences, accurately capturing every emotional detail and tone fluctuation, delicately restoring natural and fluent linguistic expression quality.
Personalized Voice Customization: Users can record their personal voice, and AI will precisely imitate their tone rhythm, speech rate, and pitch to generate exclusive voiceovers, meeting brand or individual personalization needs.
Diverse Voice Generation: Leveraging diversity generation capabilities, it can automatically generate multiple voice versions with different styles from the same text, adapting to different creative scenarios.
ViiTor AI's core advantage lies in balancing speech refinement with practical usability. Its AI speech naturalness rivals human speech, and the platform features comprehensive speech regulation functions supporting user fine-tuning of volume and speech rate, while covering 5 common emotion adaptations. It can precisely match various creative scenarios until achieving voiceover effects that meet project requirements. This refined and diversified regulation capability is currently beyond Cartesia's reach.
ViiTor AI also adapts to professional office scenarios, seamlessly integrating with various tools used in daily team operations, while offering enterprise-level security protection, compliance certification, and reliable technical support. Combined with its commitment to ethical AI development principles, it has become a premium speech service platform capable of long-term empowerment for enterprises and creators.
If Cartesia can be compared to an industry newcomer with unlimited potential, then ViiTor AI is a deeply experienced, trusted expert in the field, capable of completing various voice creation tasks stably and efficiently.
Although Cartesia is a new entrant in the text-to-speech field, its innovative technology has indeed attracted industry attention. However, in practical application scenarios, many creators and enterprises need not just technological innovation, but also stable performance, comprehensive advanced features, and scalable capabilities—this is precisely ViiTor AI's core value. With professional-grade text-to-speech performance, massive high-quality voice libraries, powerful customization capabilities, and enterprise-level integration capabilities, ViiTor AI is not an experimental tool but a comprehensive AI speech technology solution capable of meeting various scenario needs.