ViiTor-Voice: A New Era of Open-Source Voice Interaction
In the digital age, AI technology is transforming how we live and work at an unprecedented pace. Imagine being able to make any digital character speak in real-time with a voice that sounds as natural as a human. This is exactly what ViiTor AI's newly released open-source model, ViiTor-Voice AI, can do. Designed for efficient and low-latency intelligent voice interactions, it generates hundreds of voice tones, bringing virtual conversations to life. Whether you’re a game developer looking to voice characters, a content creator seeking diverse narration styles, or someone wanting to make your smart assistant sound friendlier, ViiTor-Voice can meet your needs and usher in a new era of intelligent interaction.
⚡️ Real-Time Efficiency and Lightweight Deploymen
🚀 Real-Time Streaming Output with Ultra-Low Latency
On the Tesla T4 platform, the ViiTor-Voice model achieves an industry-leading 200-millisecond first-frame latency for streaming output. Compared to Fish Speech’s 500 milliseconds and CosyVoice’s 800 milliseconds, ViiTor-Voice offers near-instant feedback, making it ideal for applications requiring fast responses. Whether it’s online customer service, smart assistants, or real-time translation, it ensures a seamless and smooth user experience.
🌟 Lightweight Design for Perfect Performance and Resource Optimization
With a 0.5B parameter lightweight design, our model ensures seamless compatibility with large language model (LLM) inference engines. The token-to-audio decoder in ViiTor-Voice is compact, allowing token-based transmission between servers and clients, with decoding handled on the client side for improved efficiency. This design not only delivers high performance but also optimizes computational resource usage to the fullest. Whether on servers, mobile devices, or edge computing environments, our model is easy to deploy, catering to diverse needs.
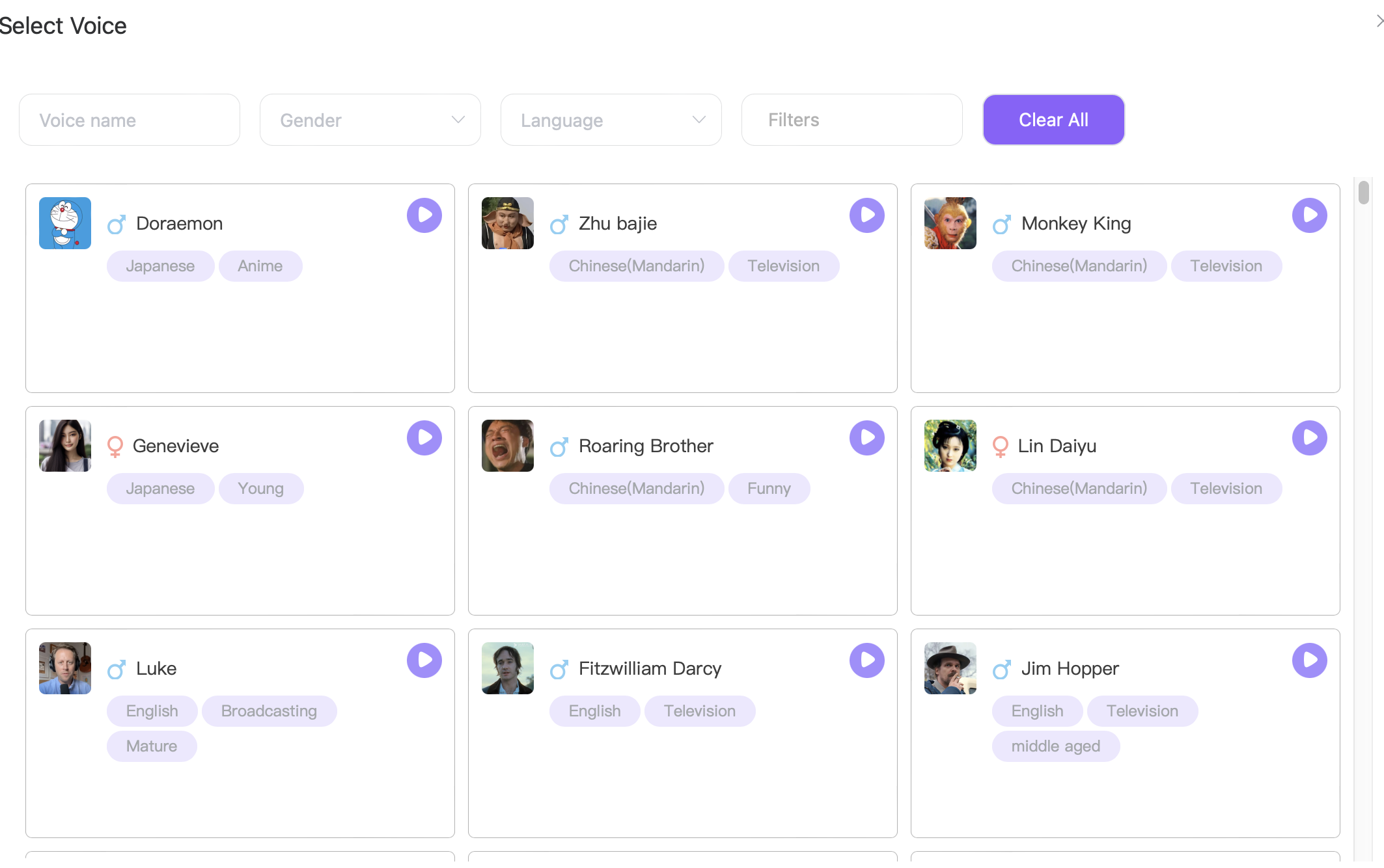
🎙️ Rich Voice Library with Personalized Options
We provide over 300 distinct voice options, enabling you to select the perfect voice style for different scenarios and personal preferences. From business meetings and podcasts to voiceovers for virtual characters, our model ensures every expression is unique and suited to your needs.
⏱️ Flexible Speech Rate Adjustment for Natural, Smooth Communication
Our model supports natural variations in speech rate, allowing users to easily adjust based on content requirements and audience preferences. Whether speeding up for efficient information delivery or slowing down for emotional depth, it maintains a natural and smooth linguistic flow.
🔬 Coming Soon: Zero-Shot Voice Cloning
The ViiTor-Voice model, with its decoder-only architecture, is inherently capable of zero-shot cloning. We are currently developing features to enable rapid voice cloning using minimal voice samples, promising to revolutionize personalized real-time voice services.
🌐 Open Source for Collaborative Innovation
We believe that openness and sharing are the keys to driving innovation. That’s why we’ve decided to open-source this model, inviting developers and researchers worldwide to contribute, optimize, and expand its functionalities, pushing the boundaries of AI technology together.
Let’s embrace this lightweight, high-performance AI voice model and unlock a new era of intelligent interaction!
Search ViiTor-Voice on GitHub or scan the QR code below to visit our GitHub page and experience the voice of the future!
2024.12.11

